35 бесплатных онлайн-курсов по data science и аналитике данных
Содержание:
- «Введение в Data Science и машинное обучение» от Института биоинформатики
- Какие профессии есть в сфере больших данных
- 19 бесплатных материалов
- «Анализ данных в R» — Stepik
- «Математика и Python для анализа данных» — Coursera
- «Как стать специалистом по Data Science» — Яндекс.Практикум
- «Машинное обучение и анализ данных» — Coursera
- «Введение в науку о данных» — Coursera
- «Что такое наука о данных» — Coursera
- 7 полезных видео на YouTube
- Полезные статьи: ТОП-6
- Big data в бизнесе
- Профильные категории и процессы Big Data проекта
- Аналитик big data, или Кто такой дата-сайентист
- Какие компании занимаются большими данными
- Каким компаниям нужны аналитики данных?
- Big data в маркетинге
- Чем конкретно занимается аналитик данных
- Как ИТ-решения и предиктивная аналитика помогают зарабатывать больше
- Примеры использования Big Data
- Плюсы и минусы профессии
- Что будет с Big Data в будущем
- Big data — простыми словами
- Полезные ссылки
- Какие используются инструменты и технологии big data
- Переход на электронные перевозочные документы ускорит логистику
- Каким должен быть специалист по большим данным
- Методики анализа и поиск зависимостей
- Особенности профессии
«Введение в Data Science и машинное обучение» от Института биоинформатики
Длительность курса: 30 уроков.
Формат обучения: видеоуроки + тесты + интерактивные задачи.
Программа обучения:
- О чём курс?
- Big Data, Deep Machine Learning — основные понятия.
- Модель, начнём с дерева.
- Pandas, Dataframes.
- Фильтрация данных
- Группировка и агрегация.
- Визуализация, seaborn.
- Практические задания: Pandas.
- Секретный гость.
- Stepik ML contest — это ещё что такое?
- Stepik ML contest — data preprocessing.
- Какого музыканта Beatles я загадал или entropy reduction.
- Немного теории и энтропии.
- Titanic: Machine Learning from Disaster.
- Обучение, переобучение, недообучение и кросс-валидация.
- Последний джедай или метрики качества модели.
- Подбор параметров и ROC and Roll.
- Практика, Scikit-learn, fit, predict, you are awesome.
- ML на практике — автокорректор ошибок правописания.
- Секретный гость.
- Stepik ML contest.
- Снова возвращаемся к деревьям.
- Random forest.
- Зачем знать что-то ещё, если есть Random Forest?
- Секретный гость.
- И на Марсе будут яблони цвести.
- Нейроэволюция.
- Трюки в Pandas.
- Вот и всё, а что дальше?
- Stepik ML contest.
Что освоите:
- Основные понятия Data Science и Machine Learning
- Наиболее популярные Python-библиотеки для анализа данных — Pandas и Scikit-learn
- Начать обучение можно сразу после регистрации
- Обучение проводят лучшие преподаватели Института биоинформатики
- Современная программа обучения
- Изложение материала простым языком
- Можно бесплатно получить сертификат по окончании обучения
Преподаватели:
Какие профессии есть в сфере больших данных
Две основные профессии — это аналитики и дата-инженеры.
Аналитик прежде всего работает с информацией. Его интересуют табличные данные, он занимается моделями. В его обязанности входит агрегация, очистка, дополнение и визуализация данных. То есть, аналитик в биг дата — это связующее звено между информацией в сыром виде и бизнесом.
У аналитика есть два основных направления работы. Первое — он может преобразовывать полученную информацию, делать выводы и представлять ее в понятном виде.
Второе — аналитики разрабатывают приложения, которые будет работать и выдавать результат автоматически. Например, делать прогноз по рынку ценных бумаг каждый день.
Дата инженер — это более низкоуровневая специальность. Это человек, который должен обеспечить хранение, обработку и доставку информации аналитику. Но там, где идет поставка и очистка — их обязанности могут пересекаться
Bigdata-инженеру достается вся черная работа. Если отказали системы, или из кластера пропал один из серверов — подключается он. Это очень ответственная и стрессовая работа. Система может отключиться и в выходные, и в нерабочее время, и инженер должен оперативно предпринять меры.
Это две основные профессии, но есть и другие. Они появляются, когда к задачам, связанным с искусственным интеллектом, добавляются алгоритмы параллельных вычислений. Например, NLP-инженер. Это программист, который занимается обработкой естественного языка, особенно в случаях, когда надо не просто найти слова, а уловить смысл текста. Такие инженеры пишут программы для чат-ботов и диалоговых систем, голосовых помощников и автоматизированных колл-центров.
Есть ситуации, когда надо проклассифицировать миллиарды картинок, сделать модерацию, отсеять лишнее и найти похожее. Эти профессии больше пересекаются с компьютерным зрением.
19 бесплатных материалов
Теперь перейдем к бесплатным материалам по аналитике данных, Machine Learning, Data Science и Big Data. Мы собрали лучшие курсы, статьи и видеоролики на YouTube для начинающих IT-специалистов.
С помощью бесплатных материалов вы освоите азы аналитики и поймете, подходит вам эта профессия или нет.
«Анализ данных в R» — Stepik
Трехнедельный курс в рамках которого вы узнаете основные этапы статистического анализа R, считывания данных, предобработки данных, визуализации результатов и применения основных статистических методов.
После завершения курса вы получите сертификат Stepik.
«Математика и Python для анализа данных» — Coursera
Обучающий курс на платформе Coursera. Проводится от партнеров: Московский физико-технический институт, E-Learning Development Fund и Яндекс.
После прохождения обучения вы получите сертификат. Примерное время прохождения: 29 часов.
«Как стать специалистом по Data Science» — Яндекс.Практикум
Обучающая программа от Яндекс.Практикум. Вы станете специалистом по Data Science: вы освоите основы Python и анализа данных, предобработку данных, статистический анализ данных.
Бесплатно доступен вводный курс. Стоимость полного обучения: 104 000 руб.
«Машинное обучение и анализ данных» — Coursera
Курс о машинном обучении и анализе данных. Типовые задачи Machine Learning и анализа данных и методы их решения.
Курс проводят партнеры Coursera: Яндекс, Московский физико-технический институт и E-Learning Development Fund.
После успешного прохождения курса вы получите сертификат.
«Введение в науку о данных» — Coursera
Курс, который поможет стать исследователем данных. Проводится от партнера Coursera компании IBM.
Приблизительное время прохождения: 4 месяца. Язык: английский. Есть русские субтитры.
«Что такое наука о данных» — Coursera
Курс на Coursera в партнерстве с IBM. Вы узнаете, что такое наука о данных.
Приблизительное время прохождения: 10 часов. В итоге вы получите сертификат.
7 полезных видео на YouTube
Также мы подготовили для вас подборку бесплатных видео на YouTube по Big Data, анализу данных и Data Science. Нашли полезных 7 роликов.
1) Видео от GeekBrains о том, что такое аналитика Big Data:
2) Все о Data Science: интервью со специалистом в этой области:
3) Интервью с создателем главного российского BigData-алгоритма Артуром Хачуяном:
4) Видео про зарплаты в Big Data:
5) Первый урок курса «Введение в Анализ Данных»:
6) Основы Python для Data Science — видео от Skillbox:
7) Видео о том, что такое Data Science:
Полезные статьи: ТОП-6
Подборка статей для самостоятельного изучения:
- Как стать экспертом в Data Science — Tproger.
- Обзор профессии Data Scientist — Блог компании «Нетология» на Habr.
- Что такое Big Data — Rusbase
- Big Data от А до Я — Habr
- Что такое аналитика данных — Oracle
- Можно без опыта: что нужно знать начинающему дата-аналитику — VC
Big data в бизнесе
Для оптимизации расходов внедрил Big data и «Магнитогорский металлургический комбинат», который является крупным мировым производителем стали. В конце прошлого года они внедрили сервис под названием «Снайпер», который оптимизирует расход ферросплавов и других материалов при производстве. Сервис обрабатывает данные и выдаёт рекомендации для того, чтобы сэкономить деньги на производстве стали.
Большие данные и будущее — одна из самых острых тем для обсуждения, ведь в основе коммерческой деятельности лежит информация. Идея заключается в том, чтобы «скормить» компьютеру большой объем данных и заставить его отыскивать типовые алгоритмы, которые не способен увидеть человек, или принимать решения на основе процента вероятности в том масштабе, с которым прекрасно справляется человек, но который до сих пор не был доступен для машин, или, возможно, однажды — в таком масштабе, с которым человек не справится никогда.
Профильные категории и процессы Big Data проекта
Независимо от конечной цели и особенностей реализации, в команде любого проекта по большим данным выполняются все процессы по стандарту CRISP-DM, от формирования бизнес-требований до внедрения программного решения на основе разработанных аналитических моделей, в т.ч. с использованием машинного обучения (Machine Learning). Сгруппировав этапы разработки ПО со стадиями CRISP-DM, можно выделить 4 профильных категории Big Data проекта, в которых задействованы различные специалисты:
- Бизнес, куда входят специалисты предметной области (эксперты, потенциальные пользователи), посредники между проблемами и техническими решениями (аналитики, консультанты), а также менеджмент (заказчик, руководитель проекта);
- Данные (Data Professionals: аналитики, архитекторы, исследователи и инженеры данных) – люди, ответственные за сбор, преобразование, управление информационными потоками и моделями, а также извлечение полезных для бизнеса сведений из массивов Big Data и мониторинг их жизненного цикла;
- Реализация – разработчики программного обеспечения (программисты, тестировщики, UI/UX-дизайнеры) и программной документации (технические писатели), а также специалисты по развертыванию приложений с функциями системных администраторов и специалистов по информационной безопасности;
- Эксплуатация – техническая поддержка пользователей, мониторинг производительности приложений и актуальности данных, обеспечение информационной безопасности, включая защиту от взломов и утечек.
Отметим, что фаза реализации является фактическим окончанием проекта, т.к. здесь поставляется итоговый результат к конечному сроку. Эксплуатация – это уже штатный процесс, который выполняется регулярно
Поэтому важно разграничить временные роли участников проекта от лиц, задействованных в процессе на постоянной основе
Профильные категории Big Data проекта
Аналитик big data, или Кто такой дата-сайентист
В современном мире информация является одним из важнейших экономических ресурсов. На основе анализа данных принимаются бизнес-решения.

Аналитики-профессионалы имеют дело с большим объемом сложно организованной и неоднородной по структуре информации: результаты опросов, исследований, показатели обслуживания клиентов и др.
Источники информации могут быть самые разнообразные: метеорологические показатели, потоки сообщений из соцсетей, непрерывные данные с измерительных приборов, устройств видеорегистрации и средств наблюдения за поверхностью Земли.
Главные задачи специалиста в этой области — выделение нужной информации, нахождение закономерностей и построение моделей.
Что такое big data:
Ключевые навыки дата-сайентиста
Стать аналитиком больших данных может не каждый. Помимо образования надо обладать следующими навыками и личными качествами:
- аналитический склад ума;
- исследовательский интерес;
- критическое мышление;
- внимательность;
- ответственность;
- усидчивость;
- быстрая обучаемость.
Для профессионального data scientist важно проанализировать всю информацию, а результаты донести простым языком, ведь на их основе руководители компаний принимают решения. Понадобится и уверенное владение английским: на нем представлена большая часть технической документации и периодических изданий в области big data
Обязанности специалиста по большим данным
Обязанности специалиста по исследованию данных сводятся к их сбору, систематизации, анализу и подготовке отчета о результатах. Аналитику big data приходится работать с разрозненной и неструктурированной информацией. Ее нужно собрать из разных источников, систематизировать, найти взаимосвязи и логические цепочки.
Выводы по итогам исследования заказчику получает в виде отчетов или презентации с рекомендациями по дальнейшим действиям.
Какие компании занимаются большими данными
Первыми с большими данными, либо с «биг дата», начали работать сотовые операторы и поисковые системы. У поисковиков становилось все больше и больше запросов, а текст тяжелее, чем цифры. На работу с абзацем текста уходит больше времени, чем с финансовой транзакцией. Пользователь ждет, что поисковик отработает запрос за долю секунды — недопустимо, чтобы он работал даже полминуты. Поэтому поисковики первые начали работать с распараллеливанием при работе с данными.
Чуть позже подключились различные финансовые организации и ритейл. Сами транзакции у них не такие объемные, но большие данные появляются за счет того, что транзакций очень много.
Количество данных растет вообще у всех. Например, у банков и раньше было много данных, но для них не всегда требовались принципы работы, как с большими. Затем банки стали больше работать с данными клиентов. Стали придумывать более гибкие вклады, кредиты, разные тарифы, стали плотнее анализировать транзакции. Для этого уже требовались быстрые способы работы.
Сейчас банки хотят анализировать не только внутреннюю информацию, но и стороннюю. Они хотят получать большие данные от того же ритейла, хотят знать, на что человек тратит деньги. На основе этой информации они пытаются делать коммерческие предложения.
Сейчас вся информация связывается между собой. Ритейлу, банкам, операторам связи и даже поисковикам — всем теперь интересны данные друг друга.
Каким компаниям нужны аналитики данных?
Большие данные — ключевой ресурс для бизнеса: их используют в IT, ритейле, финансах, здравоохранении, игровой индустрии, киберспорте, телекоме, маркетинге. Самые крутые и современные компании называют себя Data-Driven. Они принимают стратегические решения на основе данных.
«На самом деле аналитик данных нужен в любой компании, где есть данные, — уверен Артем Боровой. — Условной сети ларьков с шаурмой он тоже по-хорошему нужен, чтобы анализировать потоки, понимать, где лучше открыть новую точку, выстраивать логистику».
Вот три ситуации, в которых бизнесу может пригодиться специалист по анализу больших данных:
«Плохие» долги. В банке хотят свести к минимуму количество клиентов, которые не возвращают кредиты. Аналитик изучает, какие характеристики клиента указывают на то, будет ли он вовремя вносить платежи. На этом основании клиенту будет одобрен или не одобрен кредит.
Проверка эффективности дизайн-решения. Создатели приложения для знакомств хотят понять, как пользователи реагируют на цвет кнопки. Аналитику данных предстоит протестировать два прототипа: часть пользователей видит вариант с синей кнопкой, другая часть — с красной. В итоге он помогает дизайнеру интерфейса решить, какого цвета кнопка лучше сработает.
Еще благодаря качественному анализу данных можно:
- выявлять настоящие и будущие потребности клиентов;
- прогнозировать спрос на товар или услугу;
- оценивать вероятность ошибки при разных действиях;
- контролировать работу и износ оборудования;
- управлять логистикой;
- следить за эффективностью сотрудников.
Всё это помогает компании узнать о себе больше, увеличить прибыль и сократить издержки.
Big data в маркетинге
Благодаря Big data маркетологи получили отличный инструмент, который не только помогает в работе, но и прогнозирует результаты. Например, с помощью анализа данных можно вывести рекламу только заинтересованной в продукте аудитории, основываясь на модели RTB-аукциона.
Big data позволяет маркетологам узнать своих потребителей и привлекать новую целевую аудиторию, оценить удовлетворённость клиентов, применять новые способы увеличения лояльности клиентов и реализовывать проекты, которые будут пользоваться спросом.
Сервис Google.Trends вам в помощь, если нужен прогноз сезонной активности спроса. Всё, что надо — сопоставить сведения с данными сайта и составить план распределения рекламного бюджета.
Чем конкретно занимается аналитик данных
Основной обязанностью аналитика данных считается извлечение из Big data (больших массивов информации) сведений, которые являются наиболее значимыми для принятия лучших решений в плане эффективного управления бизнесом. В большинстве случаев аналитик big data самостоятельно обрабатывает информационные массивы. Для этого ему приходится выполнять ряд необходимых операций:
- собирать данные;
- готовить сведения к анализу (делать выборку, чистить и сортировать);
- находить закономерности в наборах информации;
- визуализировать данные для скорости восприятия и понимания готовых результатов и будущих направлений развития;
- формулировать предположения относительно повышения эффективности отдельных бизнес-метрик путем изменения других параметров.
Как ИТ-решения и предиктивная аналитика помогают зарабатывать больше
Типовые ИТ-решения управления логистикой анализируют данные из транспортных заявок в ходе управления расписанием на погрузку/разгрузку. Отдельный объём данных получают от дополнительных статусов и настроек заказчика (расход топлива, скорость обработки заказа, время хранения товара на складе и др.).
Одними из первых в России о своей трансформации с упором на big data также заявили РЖД. В конце 2019 года они анонсировали цифровую платформу мультимодальных пассажирских перевозок со следующими компонентами:
- аналитика на базе машинного обучения,
- роботизированные коммуникации с человеком,
- дополненная реальность,
- машинное зрение,
- управление пользовательским опытом.
По итогам года, эффект от нововведений составил 1,1 млрд рублей, на 17% выше запланированного. На это повлиял рост продажи электронных билетов (на 30%) через мобильное приложение и переход на безбумажный формат работы с грузовыми перевозками.

Транспортная компания ПЭК больше двух лет использует большие данные. Их собирает собственный аналитический центр управления перевозками (ЦУП). Система в режиме реального времени контролирует загрузку складов в 189 пунктах по всей России, обрабатывает каждую секунду больше 500 операций и составляет прогнозы на ближайший месяц. Вот список технологий big data, которые использует ЦУП:
- Akka Framework для разработки параллельных и распределенных микросервисов на JVM;
- Spark Streaming для потоковой обработки больших данных;
- Apache Kafka для обмена сообщениями между сервисами;
- Apache Hadoop для хранения исторических данных;
- PostgreSQL для срочной отчетности;
- оперативные данные хранятся в памяти (IMDB, In-memory Database).
В ГК «Деловые линии» отмечают, что их опыт внедрения big data позволил оптимизировать затраты на топливо и улучшить сервис в компании. Сбор данных с транспортных средств и GPS-трекеров даёт оценку манеры вождения водителя, позволяет оценивать состояние машины. На основе этих данных водителям можно предлагать рекомендации по безопасному и экономичному движения, а аналитикам — тестировать гипотезы. Кроме того, у компании есть стратегический партнёр BIA-Теchnologies, который реализовал комплексный проект на технологической базе Hadoop, Qlik View и специально разработанного Self-service BI. Это инструмент для b2b-сегмента, который сократил время подготовки отчетов в 2—3 раза, уменьшил издержки на работе персонала и расходе топлива и в целом улучшил качество обслуживания.
Компаниям не обязательно нужно создавать собственные решения для грузоперевозок. На рынке развиваются аналитические сервисы, которые позволяют оптимизировать маршруты под запросы, оценивают скорость и качество работы водителей и даже регулируют количество транспорта в парке.
Например, сервис Relog помог быстрее обрабатывать обращения аптечной сети, снизил без потери качества количество грузовиков в автопарке ― с 12 до 10 и сократил расходы компании на 22—29% даже с учётом повышения зарплат водителям.
Аналитики собрали все данные по перемещению груза в одном приложении, чтобы избежать «контрольных» звонков от диспетчеров, предоставили программу для эффективного расчёта маршрутов. Система выстроила новые геозоны, исходя из загруженности аптек в каждом «квадрате» региона. Таким образом, за водителем закрепляли не просто точки на карте, а загрузку. К этому добавили KPI и за работу на более «сложных» районах водители получали хорошую доплату и мотивацию сделать работу в срок.
Примеры использования Big Data
- создания контента для разной целевой аудитории;
- разработки персональных рекомендаций;
- измерения эффективности контента.
Например, музыкальный сервис Spotify использует big data для сбора данных от миллионов пользователей по всему миру, а затем использует проанализированные данные для предоставления музыкальных рекомендаций отдельным пользователям.
Рекламодатели – одни из крупнейших игроков в сфере больших данных. Facebook, Google, Яндекс или любой другой онлайн-гигант – все они отслеживают поведение пользователей. В результате они предоставляют рекламодателям большой объем данных для точной настройки кампаний. Возьмем, к примеру, Facebook. Здесь можно выбрать аудиторию на основе покупательского намерения, посещений веб-сайтов, интересов, должности, демографии и т.д. Все эти данные собираются алгоритмами Facebook с использованием методов анализа big data.
Логистика
Логистические компании уже довольно давно используют аналитику для отслеживания заказов и составления отчетов. Благодаря большим данным можно отслеживать состояние товаров в пути и оценивать потери. В режиме реального времени собираются данные о дорожном движении, погодных условиях и определяются маршруты для транспортировки грузов. Это помогает логистическим компаниям снизить риски, повысить скорость и надежность доставки.
Медицина
Большие данные в здравоохранении используются для улучшения качества жизни, лечения болезней, сокращения непроизводительных затрат, прогнозирования эпидемий. Используя big data, больницы могут повысить уровень обслуживания пациентов.
Розничная и оптовая торговля
Взаимодействие с поставщиками, покупателями, анализ запасов на складе, прогнозирование продаж – это лишь часть функций, с которыми помогает справляться Big Data.
Государственные структуры
В качестве примеров: учет налоговых поступлений, сбор и анализ данных, собранных в интернете (новости, социальные сети, форумы и т.д.) для противодействия экстремизму и организованной преступности, оптимизация транспортной сети, выявление районов избыточной концентрации работающего, проживающего или незанятого населения, изучение предпосылок к развитию территорий и так далее.
Банковская сфера
Сбор и анализ информации помогает банкам бороться с мошенничеством, эффективно работать с клиентами (сегментировать, проводить оценку кредитоспособности клиентов, предлагать новые продукты), управлять работой отделений (например, прогнозировать очереди, нагрузку специалистов и так далее).
Предупреждение природных и техногенных катастроф
Множество машин ежедневно отслеживают сейсмическую активность в режиме реального времени. Это позволяет ученым спрогнозировать землетрясение. Даже обычным пользователям интернета также доступны эти инструменты наблюдений: есть различные, на которых представлены интерактивные карты.
Для сохранения безопасности на предприятиях также внедряются технологии, позволяющие обнаруживать и прогнозировать риски и предотвращать несчастные случаи.
Плюсы и минусы профессии
Плюсы
- Профессия новая и стремительно набирает популярность.
- Большое количество клиентов заинтересовано в услугах Big Data Analyst.
- Специалисты по большим данным получают высокую заработную плату.
- Возможность получить работу мечты в крупной российской компании, например, «Яндекс» или Mail.ru Group, или деловое предложение от зарубежных корпораций, холдингов: аналитика Big Data – это дорогое удовольствие, позволить его себе могут только гиганты бизнеса или госструктуры.
- Возможен профессиональный рост и смена профиля деятельности.
Минусы
- Работа малоподвижная и однообразная.
- Часто ненормированый рабочий день.
- Постоянное психологическое напряжение.
- Нет вакансий в небольших городах, но этот недостаток компенсируется возможностью работать удаленно.
Что будет с Big Data в будущем
Большие данные уже меняют правила игры во многих областях и, несомненно, будут продолжать расти. Объем доступных нам данных будет только увеличиваться, а технологии аналитики станут более совершенными. Большие данные – это одна из тех вещей, которые будут определять будущее человечества.
Тем не менее, еще в 2015 году компания Gartner, которая специализируется на исследованиях рынка информационных технологий, исключила Big Data из числа популярных трендов. С этого времени «большие данные» стали квалифицироваться как рабочий инструмент, а на смену им пришел новый тренд – Smart Data.
Если Big Data представляет собой огромный массив данных, то Smart Data – это уже «обработанные», ценные данные, необходимые для решения конкретных бизнес-задач. На первый план здесь выходит не количество, а качество исходных данных.
Таким образом, можно сказать, что «большие данные» превращаются в «умные данные», когда они собираются и оптимизируются с учетом конкретных потребностей отрасли и отдельной организации. Smart Data не только помогает компаниям понять, что происходит в данный момент, но и почему это происходит. Использование интеллектуальных данных позволяет компаниям лучше понимать поведение своих клиентов, предоставлять подходящие услуги/продукты, улучшать бизнес-операции, а также получать более высокий уровни дохода.
Big data — простыми словами
В современном мире Big data — социально-экономический феномен, который связан с тем, что появились новые технологические возможности для анализа огромного количества данных.
Для простоты понимания представьте супермаркет, в котором все товары лежат не в привычном вам порядке. Хлеб рядом с фруктами, томатная паста около замороженной пиццы, жидкость для розжига напротив стеллажа с тампонами, на котором помимо прочих стоит авокадо, тофу или грибы шиитаке. Big data расставляют всё по своим местам и помогают вам найти ореховое молоко, узнать стоимость и срок годности, а еще — кто, кроме вас, покупает такое молоко и чем оно лучше молока коровьего.
Кеннет Кукьер: Большие данные — лучшие данные
Полезные ссылки
- бесплатные курсы: Основы статистики;
- тренажеры: SQL;
- полезные материалы по продуктовой аналитике от команды МатеМаркетинга;
- чат с вакансиями в сфере анализа данных;
- канал с полезными материалами про работу с данными.
Артем Боровой: На мой взгляд, самый удобный путь — начать применять инструменты аналитика в своей текущей работе. Можно постепенно изучать языки и программы, а потом использовать их для своих задач. Конечно, не у всех может быть доступ к данным по месту работы, но для таких случаев есть площадки для самостоятельного обучения. Онлайн-курсы в этом плане проще и удобнее, так как человеку не нужно самому отбирать информацию, они помогают пройти по всем важным пунктам, дают материал в нужном темпе, погружают в комьюнити.
Какие используются инструменты и технологии big data
Поскольку данные хранятся на кластере, для работы с ними нужна особая инфраструктура. Самая популярная экосистема — это Hadoop. В ней может работать очень много разных систем: специальных библиотек, планировщиков, инструментов для машинного обучения и многого другое. Но в первую очередь эта система нужна, чтобы анализировать большие объемы данных за счет распределенных вычислений.
Например, мы ищем самый популярный твит среди данных разбитых на тысяче серверов. На одном сервере мы бы просто сделали таблицу и все. Здесь мы можем притащить все данные к себе и пересчитать. Но это не правильно, потому что очень долго.
Поэтому есть Hadoop с парадигмами Map Reduce и фреймворком Spark. Вместо того, чтобы тянуть данные к себе, они отправляют к этим данным участки программы. Работа идет параллельно, в тысячу потоков. Потом получается выборка из тысячи серверов на основе которой можно выбрать самый популярный твит.
Map Reduce более старая парадигма, Spark — новее. С его помощью достают данные из кластеров, и в нем же строят модели машинного обучения.
Переход на электронные перевозочные документы ускорит логистику
В 2019 году Минтранс и ГИБДД совместно с участниками рынка перевозок провели ведомственный эксперимент по применению электронных транспортных накладных и путевых листов. В данный момент принят закон и часть актов, регулирующих оборот электронных транспортных накладных.
Однако законопроекты об электронных путевых листах и дистанционном телемедицинском осмотре водителей сейчас находятся в процессе согласования. Прогноз по принятию — зимняя-весенняя сессия Госдумы.
Активно развивается в направлении электронных путевых листов (ЭПЛ) ИТ-компания «СберКорус». Она ставит перед собой цель стать лидером в сфере ЭДО и реализует проекты по переводу в электронный вид транспортных документов. В месяц обрабатывает 1,5 млн электронных документов для 250 000 клиентов. Один из ярких примеров — сотрудничество с X5 Group. Компании взаимодействуют в рамках подключения ЭДО, а в 2021 году начали совместный перевод транспортных накладных в электронный вид. Нововведения сократили время простоя транспорта. Раньше обработка накладных занимала 10 минут, а теперь проверку проводят автоматически — за минуту.

И если пока что применение ЭТРН в рамках ЭДО было редкостью, то планируется, что к 1 января 2022 года будет сформирована нормативно-правовая база. Вступят в силу поправки в законодательство, закрепляющие возможность применения электронных перевозочных документов на автомобильном транспорте всеми участниками перевозочного процесса. Сначала использование ЭДО будет добровольным, а с 2023 года обязательным. К 2024 году обязательными станут и ЭПЛ.
Каким должен быть специалист по большим данным
Поскольку данные расположены на кластере серверов, для их обработки используется более сложная инфраструктура. Это оказывает большую нагрузку на человека, который с ней работает — система должна быть очень надежной.
Сделать надежным один сервер легко. Но когда их несколько — вероятность падения возрастает пропорционально количеству, и так же растет и ответственность дата-инженера, который с этими данными работает.
Аналитик big data должен понимать, что он всегда может получить неполные или даже неправильные данные. Он написал программу, доверился ее результатам, а потом узнал, что из-за падения одного сервера из тысячи часть данных была отключена, и все выводы неверны.
Взять, к примеру, текстовый поиск. Допустим все слова расположены в алфавитном порядке на нескольких серверах (если говорить очень просто и условно). И вот отключился один из них, пропали все слова на букву «К». Поиск перестал выдавать слово «Кино». Следом пропадают все киноновости, и аналитик делает ложный вывод, что людей больше не интересуют кинотеатры.
Поэтому специалист по большим данным должен знать принципы работы от самых нижних уровней — серверов, экосистем, планировщиков задач — до самых верхнеуровневых программ — библиотек машинного обучения, статистического анализа и прочего. Он должен понимать принципы работы железа, компьютерного оборудования и всего, что настроено поверх него.
В остальном нужно знать все то же, что и при работе с малыми данным. Нужна математика, нужно уметь программировать и особенно хорошо знать алгоритмы распределенных вычислений, уметь приложить их к обычным принципам работы с данными и машинного обучения.
Методики анализа и поиск зависимостей
Как это работает на практике? Рассмотрим элементарный пример, позволяющий понять, суть анализа данных.
Предположим, у вас есть некоторые данные — результаты проведенных экспериментов. Чтобы выполнить прогнозирование, необходимо установить зависимость между этими данными. Допустим, вы получили в свое распоряжение массив данных с опытами по растягиванию пружины. Вы имеете два типа данных: Y — сила, которая прикладывалась к пружине и X — длина ее деформации при этом. Попробуем представить эти данные в виде графика.
Визуализируем эту информацию на Python, используя библиотеку (для установки выполним команду )
Далее — заведем массив данных и построем точечный график.
import matplotlib.pyplot as plt X = (0, 1, 2, 3, 4, 5) Y = (0, 1000, 2000, 3000, 4000, 5000) plt.scatter(X, Y_pred, c='r') plt.plot(X, Y_pred) plt.show()
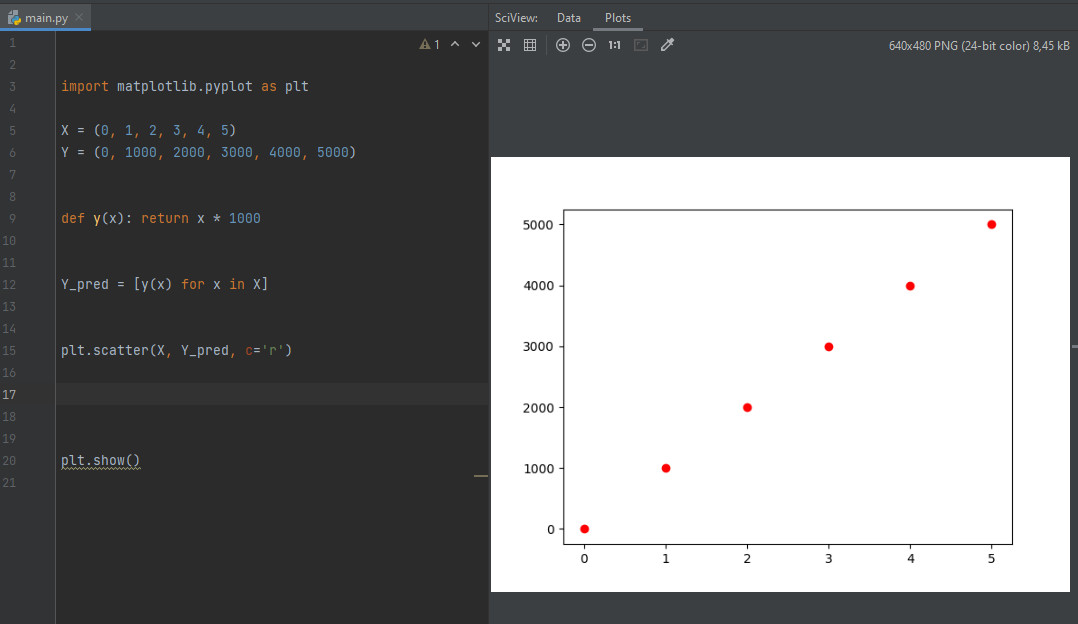
Все данные подчиняются одной и той же линейной зависимости
Как видите, эти данные, с определенной погрешностью, располагаются вдоль прямой линии. Из этого можно сделать вывод, что все данные подчиняются одной и той же линейной зависимости. Построив ее, мы можем сделать относительно точный прогноз — какую силу нужно приложить, чтобы растянуть пружину на заданную длину.
Из графика мы видим, что любая деформация помноженная на некоторый коэффициент (в нашем случае — 1000) дает результат. Таким образом, очевидно, что если взять график этой функции для нового «эксперимента», мы без труда найдем нужную точку — «предсказав» результат.
import matplotlib.pyplot as plt X = (0, 1, 2, 3, 4, 5, 2.5) Y = (0, 1000, 2000, 3000, 4000, 5000) def y(x): return x * 1000 Y_pred = plt.scatter(X, Y_pred, c='r') plt.plot(X, Y_pred) plt.show()
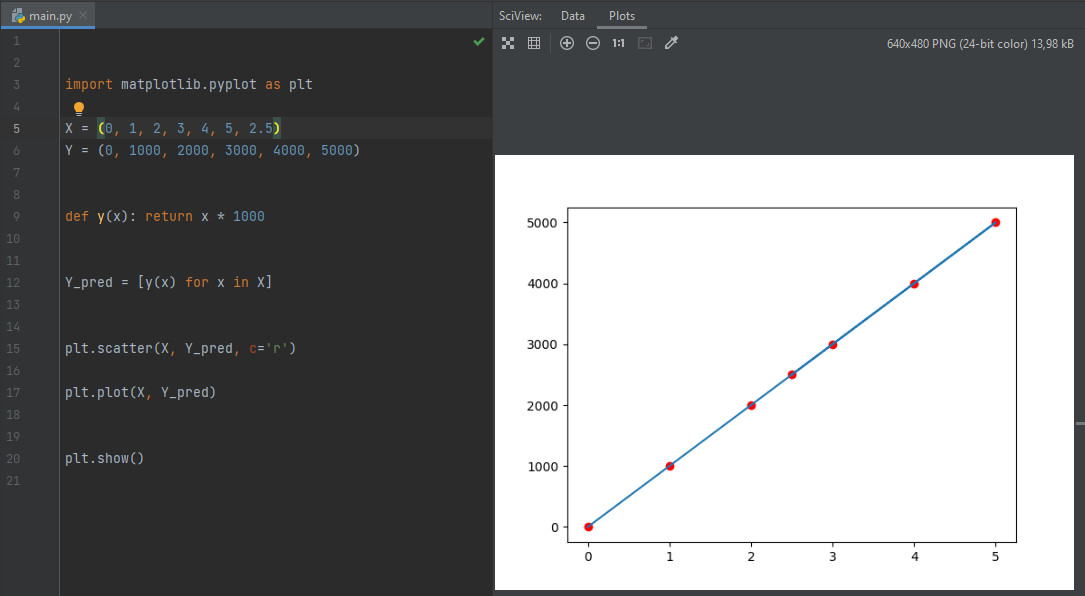
Принцип прогнозирования одинаковый для всех функций
Разумеется, это очень упрощенный вариант того, как работает Data Scientist. Зачастую определить зависимость очень сложно, да и графики для ее определения, порой, приходится делать трехмерными, чтобы получить специфический срез. Однако, принцип прогнозирования остается тем же.
Чтобы определить зависимость, повсеместно используется машинное обучение. В результате обработки данных нейронная сеть автоматически вычисляет зависимости. Механизмы, высчитывающие закономерности, базируются на теории алгоритмов, математическом анализе, линейной алгебре и статистике.
Особенности профессии
Анализ больших данных позволяет создавать новые продукты, искать точки роста для бизнеса или, если, например, речь о применении в медицине, – выявлять причины развития заболеваний. Big Data Analyst ежедневно обрабатывает колоссальное количество данных, стремясь извлечь из них информацию, которая играет важную роль для бизнеса (спрос, предложение, конкуренция, ценовая политика на рынке и т. д.). Кроме этого, аналитик больших данных может разрабатывать модели машинного обучения.
В целом Big Data Analyst выполняет следующие задачи:
- собирает необходимые данные и готовит их к анализу;
- проводит дескриптивный анализ, интерпретирует и визуализирует данные;
- создает гипотезы, которые помогут принять решения.
Во время работы аналитик больших данных выявляет логические связи, на базе которых создаются новые стратегии.
Главный инженер «Сбера» по разработке в Data Analytics
Big Data Analyst может выполнять часть обязанностей Data Scientist и Business Intelligence, но все зависит от требований работодателя.
Главный инженер «Сбера» по разработке в Data Analytics